Wonbong Jang / Won
Hello! My name is Wonbong, though you can also call me Won.
I recently finished my postdoctoral research at Meta's London office, on the MGenAI team, working on video generation, novel view synthesis and camera understanding using Diffusion Models.
I completed my PhD at University College London under
Prof. Lourdes Agapito,
learning to reconstruct 3D from RGB images.
Email / Google Scholar / Twitter / LinkedIn / Threads |

|
Papers
|
Rays as Pixels: Learning A Joint Distribution of Videos and Camera Trajectories Wonbong Jang, Shikun Liu, Soubhik Sanyal, Juan Camilo Perez, Kam Woh Ng, Sanskar Agrawal, Juan-Manuel Perez-Rua, Yiannis Douratsos, Tao Xiang ICML, 2026 Also at Video World Model Workshop, CVPR 2026 (non-archival track) Project Page / Paper / arXiv Rays as Pixels represents each camera as dense ray pixels (raxels) and denoises them jointly with video frames in a single video diffusion model. A decoupled self-cross attention mechanism lets one model predict camera trajectories from video, generate videos from one or more input images, and render novel views along a user-specified trajectory, with forward and inverse predictions that agree in a closed-loop self-consistency test. This is the first work that does video generation and camera pose prediction within a single model, which I've wanted to do since my early PhD days. |
|
Kaleido: Scaling Sequence-to-Sequence Generative Neural Rendering Shikun Liu, Kam-Woh Ng, Wonbong Jang, Jiadong Guo, Junlin Han, Haozhe Liu, Yiannis Douratsos, Juan C. Perez, Zijian Zhou, Chi Phung, Tao Xiang and Juan-Manuel Perez-Rua ICLR, 2026 Project Page / arXiv Kaleido pushes the idea of "3D perception is not a geometric problem, but a form of visual common sense" to novel view synthesis problem. It generates beautiful renderings and achieves per-scene optimization model with much fewer number of input images. |

|
|
DT-NVS: Diffusion Transformers for Novel View Synthesis Wonbong Jang, Jonathan Tremblay, Lourdes Agapito arxiv, 2025 Arxiv DT-NVS extends NViST by leveraging diffusion models, an approach well-suited for the inherently probabilistic nature of novel view synthesis in occluded regions. The method maintains consistency with the input image while generating diverse outputs for these unseen parts, as shown in the teaser figure with an occluded car. This research was completed during the final stages of my PhD studies and is available on arXiv. |

|
|
Pow3R: Empowering Unconstrained 3D Reconstruction with Camera and Scene Priors Wonbong Jang, Philippe Weinzaepfel, Vincent Leroy, Lourdes Agapito, Jerome Revaud CVPR, 2025 Project Webpage / Paper / Arxiv / Poster PDF / Code DUSt3R generates 3D pointmaps from regular images without requiring camera poses. In practice, significant effort is put into camera calibration or deploying additional sensors to acquire point clouds. We present Pow3R, a single network capable of processing any subset of this auxiliary information. By incorporating priors, our method achieves more accurate and precise 3D reconstructions, multi-view depth estimation, and camera pose predictions. This approach opens new possibilities, such as processing images at native resolution and performing depth completion. Additionally, Pow3R generates pointmaps in two distinct coordinate systems, enabling the model to compute camera poses more quickly and accurately. |
|
NViST: In the Wild New View Synthesis from a Single Image with Transformers Wonbong Jang, Lourdes Agapito CVPR, 2024 Project Page / arXiv / Code / Paper Poster PDF NViST turns in-the-wild single images into implicit 3D functions with a single pass using Transformers. Extending CodeNeRF to multiple real-world scenes, Feed-forward model, Transformers. |
|
|
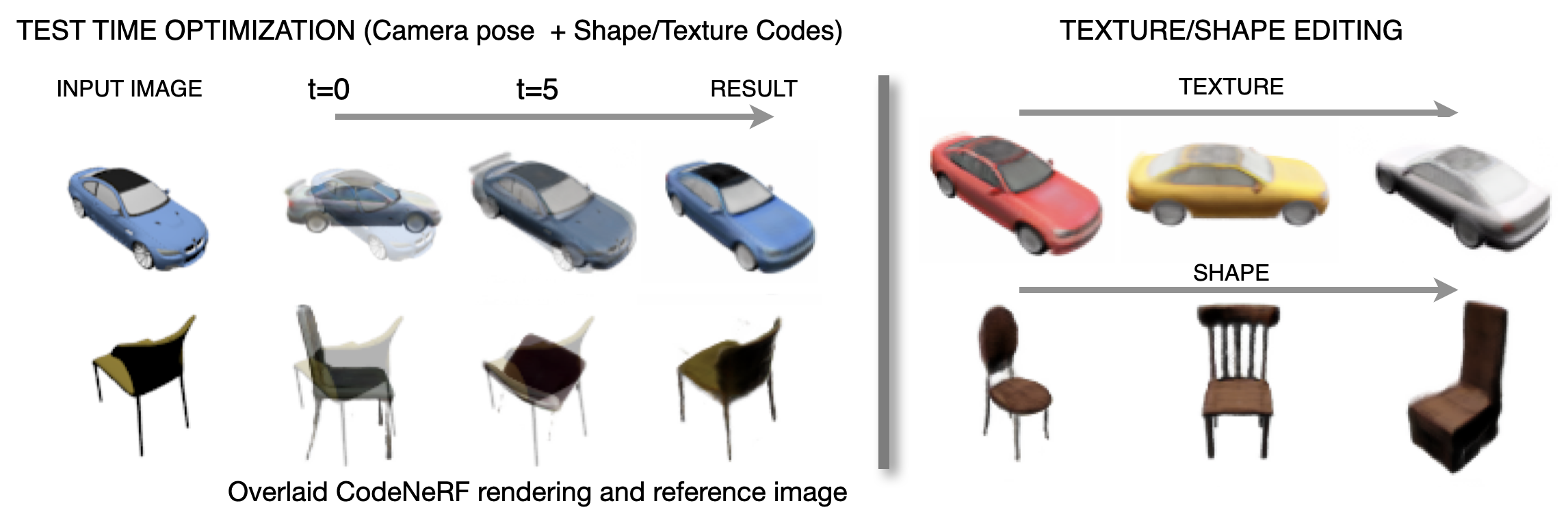
CodeNeRF: Disentangled Neural Radiance Fields for Object Categories Wonbong Jang, Lourdes Agapito ICCV, 2021 Project Page / arXiv / Code Disentangled NeRF, Conditional NeRF, Generalizing NeRF. |
Books and Movies
The below list contains some books and movies that I like and currently read/watch:
- What is Life?
- First You Write a Sentence
- What I Talk When I Talk About Running
- Algorithms to Live By
- Man's Search for Meaning
- Why Greatness Cannot Be Planned
- The Newsroom (Season 1)
This website's template is based on Jon Barron's website.