Key Ideas
- Jointly learning camera trajectories and video generation. A single video diffusion model predicts camera trajectories from video, and generates videos from one or more input images, optionally along a user-specified trajectory.
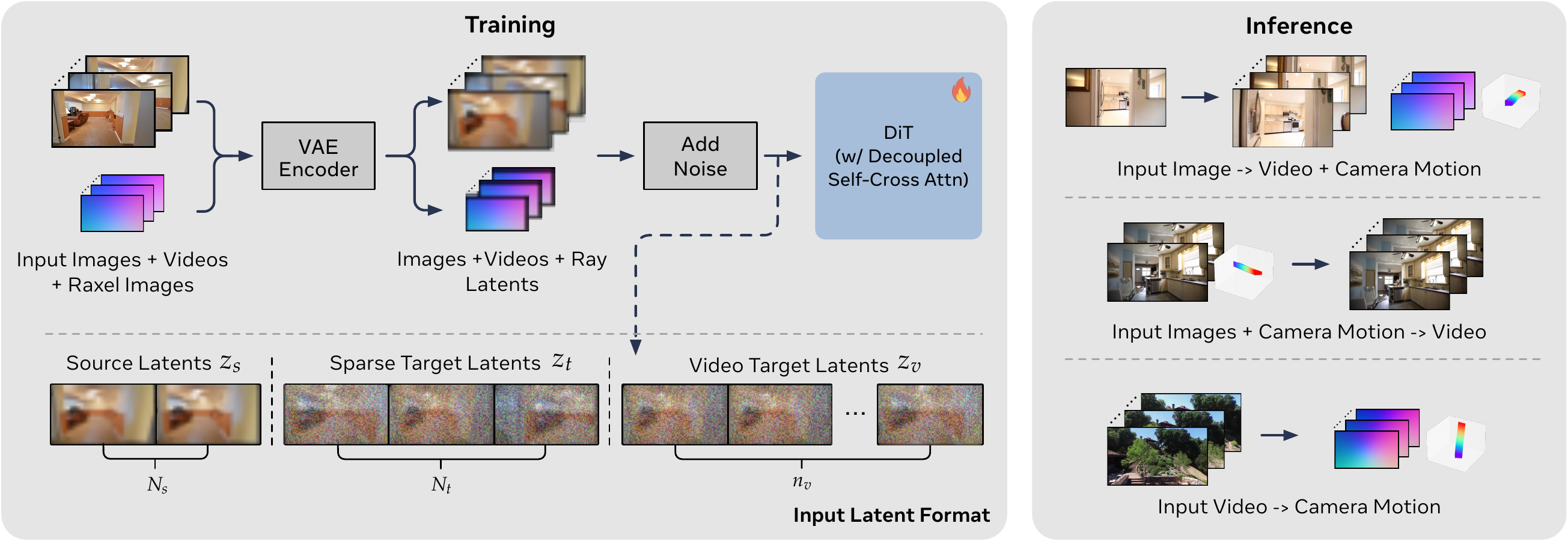
- Raxels (Rays as Pixels). Each camera is represented as dense ray pixels and denoised jointly with video frames through decoupled self-cross attention, in a shared latent space.
- Self-consistent. Forward and inverse predictions agree: generate novel views conditioned on the model's own predicted poses, and the closed loop holds.
Abstract
Recovering camera parameters from images and rendering scenes from novel viewpoints have been treated as separate tasks in computer vision and graphics. This separation breaks down when image coverage is sparse or poses are ambiguous, since each task depends on what the other produces. We propose Rays as Pixels, a Video Diffusion Model (VDM) that learns a joint distribution over videos and camera trajectories. To our knowledge, this is the first model to predict camera poses and do camera-controlled video generation within a single framework. We represent each camera as dense ray pixels (raxels), a pixel-aligned encoding that lives in the same latent space as video frames, and denoise the two jointly through a Decoupled Self-Cross Attention mechanism. A single trained model handles three tasks: predicting camera trajectories from video, generating video from input images along a pre-defined trajectory, and jointly synthesizing video and trajectory from input images. We evaluate on pose estimation and camera-controlled video generation, and demonstrate the model's self-consistency: its predicted poses and the renderings conditioned on those poses agree. Ablations against Plücker embeddings confirm that representing cameras in a shared latent space with video is substantially more effective.
Overview
At training time, input images, videos, and their ray (raxel) images are encoded by a frozen VAE and concatenated along the token axis as source latents, sparse target latents, and video target latents. We add noise and denoise the joint sequence with a DiT backbone that uses a decoupled self-cross attention block. At inference time, the same model supports three modes depending on which latents are given vs. noised: (i) input image → video + camera motion, (ii) input images + camera motion → video, and (iii) input video → camera motion. For more detail, please reference the paper.
1. Camera Pose Prediction
Given an input video, our model estimates the dense camera trajectory by denoising the ray latents conditioned on the fixed video latents. We then recover camera parameters from the predicted raxels via closed-form orthogonal Procrustes. Below, each clip visualises the input video alongside the reconstructed camera trajectory.
Layout of each clip — Left: the input video. Middle: the predicted raxel (top) and the ground-truth raxel (bottom). Right: our camera visualisation compared against ground truth (COLMAP). Since COLMAP does not recover metric scale, we align its scale to our predicted camera locations.
2. Single-Image Video Generation
Starting from a single input image, our model jointly samples a plausible camera trajectory and the corresponding video. This enables generation of scenes with large viewpoint changes where, unlike image-to-video baselines that hallucinate camera motion implicitly, the motion is explicitly represented and editable. We compare against one of the best approaches, Kaleido, on DL3DV-140 test scenes.
3. Camera-Controlled Video Generation
Given an input image and a user-specified camera trajectory, we re-render the scene as a video. We showcase four pre-defined trajectories: arc-left, arc-right, zoom-in, and zoom-out, to demonstrate controllable viewpoint synthesis from a single image.
4. Ablation Study & Self-Consistency
We qualitatively compare our full model against three variants: without decoupled attention (No Decoupled), without cosine-similarity loss (No Cosine), and a Plücker-embedding baseline (Plücker) in which rays are concatenated channel-wise with video latents rather than represented as pixel-aligned raxels. Quantitative metrics (FID / FVD / Rerr / Terr) are reported in the paper.
BibTeX
@inproceedings{jang2026raysaspixels,
title = {Rays as Pixels: Learning a Joint Distribution of Videos and Camera Trajectories},
author = {Jang, Wonbong and Liu, Shikun and Sanyal, Soubhik and Perez, Juan Camilo and Ng, Kam Woh and Agrawal, Sanskar and Perez-Rua, Juan-Manuel and Douratsos, Yiannis and Xiang, Tao},
booktitle = {International Conference on Machine Learning (ICML)},
year = {2026},
eprint = {2604.09429},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
url = {https://arxiv.org/abs/2604.09429}
}